컴포넌트
컴포넌트는 배포 단위다. 시스템의 구성 요소로 배포할 수 있는 가장 작은 단위다. 컴파일형 언어에서는 바이너리 파일의 결합체이고 인터프리터 언어의 경우는 소스 파일의 결합체이다.
어떤 형태로 배포되든, 잘 설계된 컴포넌트라면 반드시 독립적으로 배포 가능한, 따라서 독립적으로 개발 가능한 능력을 갖춰야 한다.
컴포넌트의 간략한 역사
소프트웨어 개발 초창기에는 메모리에서의 프로그램 위치와 레이아웃을 프로그래머가 직접 제어했다. 프로그램 시작부에는 프로그램이 로드될 주소를 선언하는 오리진(origin) 구문이 나와야 했다.
*200
TLS
START, CLA
TAD BUFR
JMS GETSTR
CLA
TAD BUFR
JMS PUTSTR
JMP START
BUFR, 3000
GETSTR, 0
DCA PUTSTR
NXTCH, KSF
JMP -1
KRB
DCA I PTR
TAD I PTR
AND K177
ISZ PTR
TAD MCR
SZA
JMP NXTCH
K177, 177
MCR -17(무슨 말인지 알 수도 없고 알기도 싫은 코드다..)
프로그램 시작부에 있는 *200을 주목하자. 이 명령어는 메모리 주소 200₈에 로드할 코드를 생성하라고 컴파일러에 알려준다. 오늘날의 프로그래머는 프로그램을 메모리의 어느 위치에 로드할지 고민할 필요가 없으나 초창기에는 프로그래머가 직접 정해야했다.
이 시절엔 프로그램의 위치가 한 번 결정되면 재배치가 불가능했다.
이런 구시대에는 라이브러리 함수에 어떻게 접근했을까? 프로그래머가 라이브러리 함수의 소스 코드를 애플리케이션 코드에 직접 포함시켜 단일 프로그램으로 컴파일했다. 라이브러리는 바이너리가 아니라 소스 코드 형태로 유지되었다.
그러나 장치는 느리고 메모리는 너무 비싸서 자원이 한정적이었다. 컴파일러는 소스 코드 전체를 여러 번에 걸쳐서 읽어야 했지만, 메모리가 너무 작아서 소스 코드 전체를 메모리에 상주시킬 수가 없었고 컴파일러는 소스 코드를 여러 차례 읽어야 했다. 이 과정은 몇 시간씩 걸리는 작업이었다.
라이브러리 코드 분리
컴파일 시간을 단축시키기 위해 프로그래머는 함수 라이브러리의 소스 코드를 애플리케이션 코드로부터 분리했다.
함수 라이브러리를 개별적으로 컴파일하고, 컴파일된 바이너리를 특정 위치에 로드했다. 함수 라이브러리에 대한 심벌 테이블을 생성한 후, 이를 이용해 애플리케이션 코드를 컴파일했다.
컴파일/링킹에서 심벌(Symbol)은 소스 코드 상의 변수명, 함수명, 클래스명 등과 같은 식별자를 의미한다. 심벌 테이블은 이러한 식별자와 그에 관련된 메모리 위치를 저장하는 매핑 테이블이다.
그리고 애플리케이션을 실행해야 한다면 바이너리 함수 라이브러리를 로드한 다음 애플리케이션을 로드했다. 그럴 경우에 아래와 같이 메모리가 배치되었다.
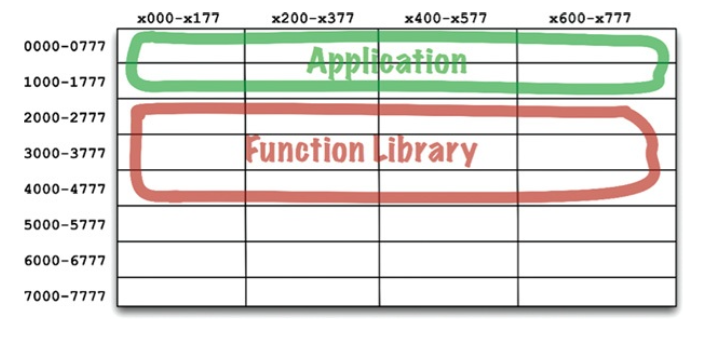
처음엔 잘 동작했지만 애플리케이션이 점점 커지면서 결국 할당된 공간을 넘어서게 되었다. 이 시점이 되면 프로그래머는 애플리케이션을 두 개의 주소 세그먼트로 분리하여 함수 라이브러리 공간을 사이에 두고 오가며 동작하게 배치해야 한다.
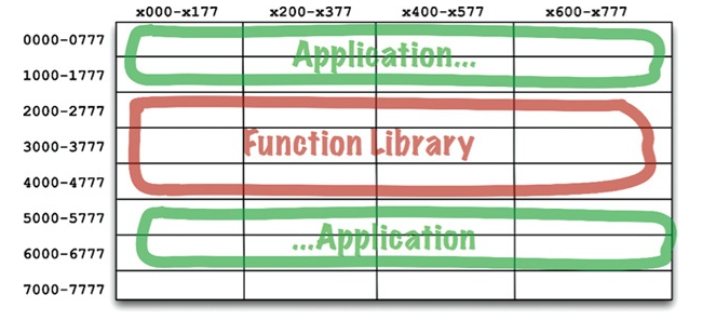
하지만 이러한 상황은 지속 가능하지 않았다. 함수 라이브러리가 커질수록 할당된 메모리 주소를 넘어서게 되고 결국 추가 공간을 할당해야 한다. 프로그램과 라이브러리가 사용하는 메모리가 늘어날수록 이와 같은 단편화는 계속될 수 밖에 없었다.
재배치성
해결책은 재배치가 가능한 바이너리였다. 지능적인 로더를 사용하여 메모리에 재배치할 수 있는 형태의 바이너리를 생성하도록 컴파일러를 수정하자는 것이다. 이 때 로더는 재배치 코드가 자리할 위치 정보를 전달받고 재배치 코드에는 로드한 데이터에서 어느 부분을 수정해야 정해진 주소에 로드할 수 있는지 알려주는 플래그가 추가되었다.
이를 통해 프로그래머는 라이브러리를 로드할 위치와 애플리케이션을 로드할 위치를 로더에게 지시할 수 있게 되었다. 이를 통해 오직 필요한 함수만을 로드할 수 있게 되었다.
또한 컴파일러는 재배치 가능한 바이너리 안의 함수 이름을 메타데이터 형태로 생성하도록 수정되었다. 만약 프로그램이 라이브러리 함수를 호출한다면 컴파일러는 라이브러리 함수 이름을 외부 참조로 생성했다. 반면 라이브러리 함수를 정의하는 프로그램이라면 해당 이름을 외부 정의로 생성했다.
이렇게 하여 외부 정의를 로드할 위치가 정해지면 로더가 외부 참조를 외부 정의에 링크시킬 수 있게 된다. 이렇게 링킹 로더(linking loader)가 탄생했다.
링커
링킹 로더의 등장으로 프로그래머는 프로그램을 개별적으로 컴파일하고 로드할 수 있는 단위로 분할할 수 있게 되었다. 작은 프로그램과 비교적 작은 라이브러리를 링크할 때는 이러한 방식이 대체로 잘 동작했다.
1960년대 말과 1970년대 초가 되자 프로그램은 훨씬 커지게 되었고 결국 링킹 로더가 너무 느려서 참을 수 없는 지경에 다다랐다. 함수 라이브러리는 자기 테이프와 같이 느린 장치에 저장되었고 링킹 로더는 대체로 느린 장치를 사용해서 수십에서 수백 개의 바이너리 라이브러리를 읽고 외부 참조를 해석해야 했다.
그래서 마침내 로드와 링크가 두 단계로 분리되었다. 프로그래머가 링크 과정을 맡았는데, 링커라는 별도의 애플리케이션으로 이 작업 처리하도록 했다. 링커는 링크가 완료된 재배치 코드를 만들어 줬고, 그 덕분에 로더의 로딩 과정이 아주 빨라졌다.
그리고 1980년대가 되어 C와 같은 고수준 언어를 사용하면서 소스 모듈은 .c 파일에서 .o 파일로 컴파일된 후, 링커로 전달되어 빠르게 로드될 수 있는 형태의 실행 파일로 만들어졌다. 각 모듈을 컴파일 하는 과정은 빨랐지만, 전체 모듈 컴파일은 꽤 시간이 걸렸다.
로드 시간은 여전히 빨랐지만 컴파일-링크 시간이 병목이었다.
1980년대 후반, 디스크는 작아지기 시작했고 아주 많이 빨라졌다. 메모리도 말도 안되게 저렴해졌다. 하드웨어의 발전이 이룩해낸 일이다.
1990년대 후반이 되자, 프로그램 성장 속도보다 링크 시간이 줄어드는 속도가 더 빨라졌다.
이렇게 Active X와 공유 라이브러리 시대가 열렸고 장치의 발전으로 로드와 링크를 동시에 할 수 있는 수준에 이르렀다. 다수의 바이너리 파일 또는 공유 라이브러리를 순식간에 서로 링크한 뒤 링크가 완료된 프로그램을 실행할 수 있게 되었다. 컴포넌트 플러그인 아키텍처가 탄생하는 순간이었다.
결론
런타임에 플러그인 형태로 결합할 수 있는 동적 링크 파일이 여기서 말하는 소프트웨어 컴포넌트에 해당한다. 이까지 오는데 50년이 걸렸지만 이제는 기본적으로 쉽게 사용할 수 있는 지점까지 왔다.
여기서 말하는 컴포넌트는 프론트엔드에서 흔히 사용하는 UI 컴포넌트와는 개념이 다르다. 마이크로 프론트엔드를 도입하지 않는 이상, 대부분의 프론트엔드 애플리케이션은 하나의 레포, 하나의 빌드, 하나의 번들로 배포된다.
따라서 물리적인 배포 단위로서의 컴포넌트는 존재하지 않는다고 볼 수 있다. 그러나 컴포넌트의 본질이 반드시 배포 단위에만 있는 것은 아니다. 프론트엔드에서도 여전히 응집도와 결합도를 다룰 수 있으며, 변경에 대한 독립성과 정책 단위의 분리, 의존성 방향을 통제하는 구조적 관점에서 컴포넌트를 정의할 수 있다.