객체 지향 프로그래밍
좋은 아키텍처를 만드는 일은 객체 지향 설계 원칙을 이해하고 응용하는 데서 출발한다. 그렇다면 객체 지향(Object-Oriented)이란 무엇인가?
누구는 "데이터와 함수의 조합"이라고 답할 수 있다. 또는 흔하게는 "실제 세계를 모델링하는 새로운 방법" 이라고들 답한다. 도대체 "실제 세계를 모델링한다"라는 말이 무엇을 의미하며, 왜 우리는 그 방향을 추구해야 하는가?
대학교 때 자바 수업을 들으며 객체 지향 프로그래밍은 실제 세계를 모델링한다라고 배웠던 기억의 편린이 있다. 그 때는 애초에 대학 수업에 관심이 없었지만... 지금 봐도 이 말은 너무 추상적이라 단번에 와닿기 쉽지 않은 설명인 거 같다. 물론 어떤 의미를 전달하려는지는 이제 안다.
OO의 본질을 설명하기 위해 캡슐화, 상속, 다형성에 기대는 사람들도 있는데 이들은 OO 언어는 최소한 세 가지 요소를 반드시 지원해야한다 말한다.
캡슐화?
OO를 정의하는 요소 중 하나로 캡슐화를 언급하는 이유는 데이터와 함수를 쉽고 효과적으로 캡슐화하는 방법을 OO가 제공하기 때문이다.
그리고 이를 통해서 데이터와 함수가 응집력 있게 구성된 집단을 서로 구분 지을 수도 있다. 구분선 밖에서 데이터는 은닉되고 공개된 일부 함수만이 외부에 노출된다. 하지만 이런 개념이 OO에만 국한된 것은 아니다. C에서도 캡슐화가 가능하다.
// point.h
struct Point;
struct Point* makePoint(double x, double y);
double distance (struct Point *p1, struct Point *p2);// point.c
#include "point.h"
#include <stdlib.h>
#include <stdio.h>
struct Point {
double x, y;
}
struct Point* makePoint(double x, double y) {
struct Point* p = malloc(sizeof(struct Point));
p->x = x;
p->y = y;
return p;
}
double distance(struct Point *p1, struct Point *p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx + dy*dy);
}C에서는 위와 같이 데이터 구조와 함수를 헤더 파일(.h)에 선언하고 그것을 구현하는 파일(.c)을 따로 뒀다.
point.h를 사용하는 측에서는 makePoint와 distance 함수를 호출할 수 있지만 내부 구현과 데이터 구조는 알 수 없다.
그러나 이후에 C++이 등장하면서 이런 완벽한 캡슐화가 깨지게 되었다. C++ 컴파일러는 클래스의 멤버 변수를 해당 클래스의 헤더 파일에 선언할 것을 요구했다. 따라서 위 코드는 아래와 같이 변경되어야 했다.
// point.h
class Point {
public:
Point(double x, double y);
double distance(const Point& p) const;
// 멤버 변수 포함
private:
double x;
double y;
}// point.cc
#include "point.h"
#include <math.h>
Point::Point(double x, double y): x(x), y(y) {}
double Point::distance(const Point& p) const {
double dx = x - p.x;
double dy = y - p.y;
return sqrt(dx*dx + dy*dy);
}point.h를 사용하는 측에서 멤버 변수 x, y를 알게 된다. 물론 직접 접근하는 일은 불가능하겠지만 변수명이 바뀌면 point.cc 파일은 다시 컴파일해야 한다.
자바같은 경우엔 헤더와 구현체를 분리하는 방식을 버렸고 클래스 선언과 정의를 구분하는 게 불가능해졌다. 캡슐화가 훼손되었다는 말이다. OO 프로그래밍은 프로그래머가 캡슐화된 데이터를 우회해서 사용하지 않을 거라는 믿음을 기반으로 한다. 그러니까 엄밀한 의미에서의 캡슐화는 C보다는 약화된 것이다.
상속?
상속이란 어떤 변수와 함수를 하나의 유효 범위로 묶어서 재정의하는 일이다. 사실 OO 언어가 있기 전에도 C 프로그래머들은 언어의 도움 없이 상속을 구현해서 썼다.
// namedPoint.h
struct NamedPoint* makeNamedPoint(double x, double, y, char* name);
void setName(struct NamedPoint* np, char* name);
char* getName(struct NamedPoint* np);// namedPoint.c
#include "namedPoint.h"
#include <stdlib.h>
struct NamedPoint {
double x, y;
char* name;
}
struct NamedPoint* makeNamedPoint(double x, double y, char* name) {
/* ... */
}
void setName(struct NamedPoint* np, char* name) {
np->name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
}// main
#include "point.h"
#include "namedPoint.h"
#include <stdio.h>
int main(int ac, char** av) {
/* ... */
printf("distance=%f\n",
distance(
(struct Point*) origin,
(struct Point*) upperRight)); // 업캐스팅
}하지만 이는 상속을 흉내내는 것에 불과했고 언어에서 상속을 지원하는 OO 언어만큼 편리한 방식은 절대 아니었다. 다중 상속을 구현하는 것은 더더욱 어려운 일이었을 것이다. 그리고 NamedPoint의 인자를 Point로 타입을 강제로 변환한 것도 볼 수 있다. OO 언어에서는 업캐스팅이 암묵적으로 이뤄진다.
따라서 OO 언어가 상속을 만든 것은 아니지만 기존에 불편하게 구현하던 상속이란 개념을 좀 더 편리한 방식으로 제공했다고 볼 수 있다.
다형성?
C로 작성한 간단한 복사 프로그램을 살펴보자.
#include <stdio.h>
void copy() {
int c;
while ((c = getchar()) != EOF) {
putchar(c)
}
}getchar() 함수는 STDIN에서 문자를 읽는다. putchar()는 STDOUT으로 문자를 쓴다. STDIN과 STDOUT은 어떤 장치인가? 이 함수는 다형적(polymorphic)이다. 즉, 행위가 STDIN과 STDOUT의 타입에 의존한다.
유닉스 운영체제의 경우 모든 입출력 장치 드라이버가 다섯 가지 표준 함수를 제공할 것을 요구한다.
- 열기(open)
- 닫기(close)
- 읽기(read)
- 쓰기(write)
- 탐색(seek)
FILE 데이터 구조는 이 다섯 함수를 가리키는 포인터들을 포함한다.
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
}콘솔용 입출력 드라이버에서는 이들 함수를 아래와 같이 정의하며, FILE 데이터 구조를 함수에 대한 주소와 함께 로드할 것이다.
#include "file.h"
void open(char* name, int mode) { /* ... */ };
void close() { /* ... */ };
int read() { /* ... */ };
void write(char) { /* ... */ };
void seek(long index, int mode) { /* ... */ };
struct FILE console = { open, close, read, write, seek }이제 STDIN을 FILE*로 선언하면 STDIN은 콘솔 데이터 구조를 가리키므로, getchar()를 아래와 같은 방식으로 구현할 수 있다.
extern struct FILE* STDIN;
int getchar() {
return STDIN->read();
}다시 말해 getchar()는 STDIN으로 참조되는 FILE 데이터 구조의 read 포인터가 가리키는 함수를 호출할 뿐이다.
void (*open)(char* name, int mode);이것을 예로 쉽게 설명해보자.
char 타입의 값의 메모리를 참조하는 name이란 이름의 파라미터와
int 타입의 mode 값을 파라미터로 받는
open 이란 이름의 함수가 있는 주소를 가리키고 있다.
즉, FILE 데이터 구조는 함수 포인터들을 갖는 인터페이스라고 볼 수 있고 입출력 드라이버는 이런 함수들을 함수 시그니처(리턴 타입, 파라미터 개수, 파라미터 타입과 순서)를 맞춰서 구현한 것이다.
이를 타입스크립트로 만든다면 아래과 같을 수 있겠다.
export interface File {
open(name: string, mode: number): void;
close(): void;
read(): number;
write(c: number): void;
seek(index: number, mode: number): void;
}export class ConsoleFile implements File {
open(name, mode): void { /* ... */ };
close(): void { /* ... */ };
read(): number { /* ... */ };
write(c: number): void { /* ... */ };
seek(index: number, mode: number): void { /* ... */ };
}1940년대 후반 폰 노이만(Von Neumann) 아키텍처가 처음 구현된 이후로 다형적 행위를 수행하기 위해서 함수를 가리키는 포인터를 써왔는데 이것이 OO가 가진 다형성의 근간이다. OO에서 새로이 만들어진 것은 아니다.
하지만 이런 함수 포인터엔 문제가 있다.
- 포인터를 초기화 해야한다
- 포인터를 통해 모든 함수를 호출해야 한다.
굉장히 추상적인 느낌으로 다가오는데 아래와 같이 예시를 살펴보자.
struct FILE console이렇게 선언만 하는 경우엔 아무 함수도 가리키지 않아서 크래식 나거나 예상치 못한 동작이 발생하게 된다. 그래서 함수 포인터를 가진 구조체는 생성 즉시 반드시 초기화해야 한다.
그리고 2번은 직접 호출과 간접 호출에 대한 이야기인데, 아래 두 함수를 살펴보자.
console_read(); // 직접 호출
STDIN->read(); // 간접 호출이렇게 된다면 직접 호출하는 경우는 구현에 직접 의존하게 되고 간접 호출하는 경우는 다형성을 만족시킨 코드가 된다. 그래서 관례적으로 구체 함수의 이름으로 호출하는 것이 아닌 함수 포인터를 통해 호출하라는 것이다.
전역으로 선언한다면 초기화 문제는 해결할 수 있지만 다형성을 만족시킬 수는 없다. 이렇듯 함수 포인터를 통한 다형성에는 휴먼 에러가 발생할 확률이 높고 이러한 버그는 찾아내고 없애기가 매우 힘들다.
OO 언어는 포인터를 언어 내부로 숨기고 컴파일러와 런타임이 그 관례를 수행해준다. 그렇기 때문에 실수할 위험이 없다. 이러한 이유로 OO는 제어흐름을 간접적으로 전환하는 규칙을 부과한다고 볼 수 있다.
다형성이 가진 힘
새로운 입출력 장치가 생긴다면 프로그램엔 어떤 변화가 생기는가? 아무런 변화가 필요하지 않다. 복사 프로그램은 입출력 드라이버의 소스 코드에 의존하지 않기 때문이다.
입출력 드라이버가 FILE 데이터 구조에 정의된 표준 함수를 잘 구현했다면 복사 프로그램에서는 얼마든지 이 입출력 드라이버를 사용할 수 있다.
천공카드로 입력을 읽고 천공카드에 출력을 생성하는 프로그램을 작성했을 때, 시간이 흘러 천공카드 대신 자기 테이프를 쓴다고 하면 그것이 잘 동작할까? 대부분의 코드를 재작성해야 할 것이다. 우리는 역사에서 프로그램은 장치 독립적이어햔다는 사실을 이미 배웠고 그렇기 때문에 유닉스는 입출력 장치들을 플러그인 형태로 만들었다.
의존성 역전
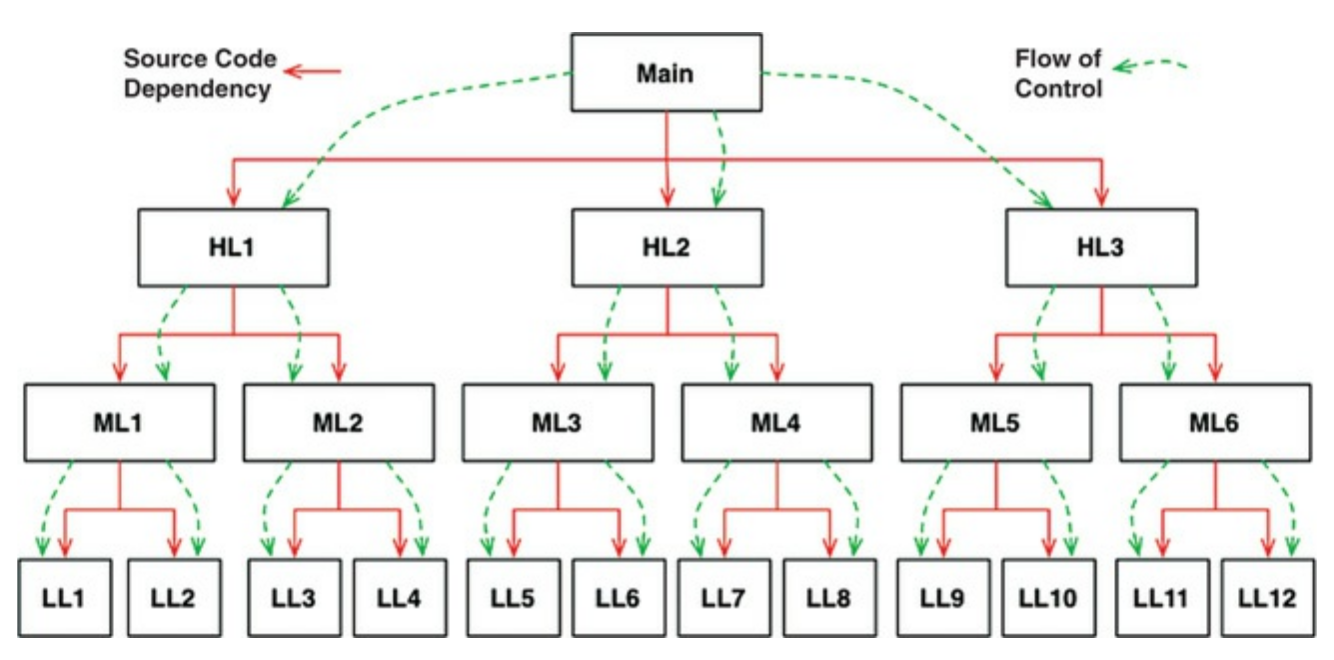
다형성을 안전하고 편리하게 적용할 수 있는 메커니즘이 등장하기 이전의 소프트웨어의 모습이다. main 함수가 고수준의 함수를 호출하고, 고수준의 함수가 상대적으로 저수준의 함수를 호출하고,,, 이런 구조가 반복되는 트리 구조이다.
고수준의 함수가 저수준의 함수를 호출하려면 해당 함수가 포함된 모듈을 가져와야 한다. C에서는 #include겠고 타입스크립트에서는 import라는 지정자를 쓴다. 모든 호출 함수는 피호출 함수가 포함된 모듈을 명시적으로 지정해야한다.
이런 제약으로 인해 아키텍트에게는 선택지가 별로 없었다. 제어흐름은 시스템의 행위에 따라 결정되며, 소스 코드 의존성은 제어흐름에 따라 결정된다.
하지만 여기서 다형성이 끼어든다면 상황은 바뀌게 된다.
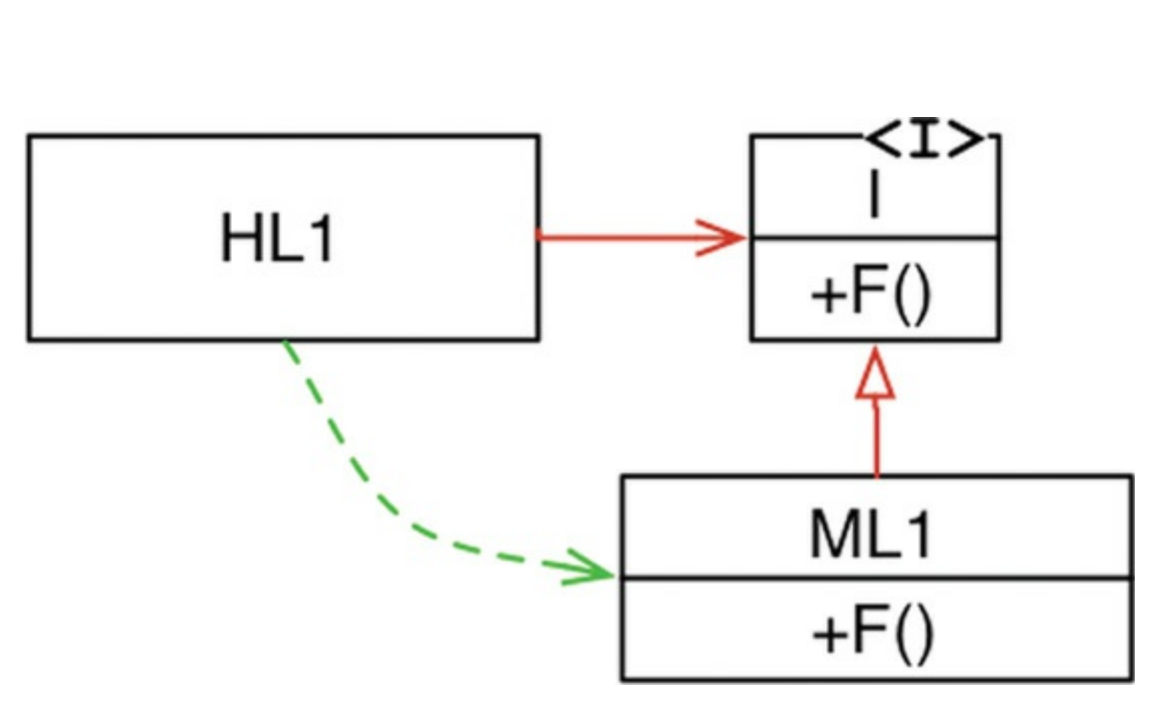
위 다이어그램을 보자. HL1 모듈은 ML1 모듈의 F() 함수를 호출한다. 고전적 구조의 경우는 아래와 같이 HL1 모듈에서 ML1 모듈을 불러와서 쓸 것이다. 그것이 위 다이어그램에서 초록색 점선 화살표가 보여주는 이용법이다.
// IFoo.ts
export interface IFoo {
F(): void;
}// HL1.ts
import type { IFoo } from './IFoo';
export function f(foo: IFoo) {
foo.F();
}// ML1.ts
import type { IFoo } from './IFoo';
export class ML1 implements IFoo {
F() { /* ... */ }
}이제 여기에 인터페이스를 하나 추가해보자. 코드 상에서 HL1 모듈은 인터페이스를 통해서 F() 함수를 호출한다. 하지만 ML1과 I 인터페이스 사이의 의존성(상속 관계)은 제어 흐름과 반대가 된다.
의존성 역전은 단순히 제어흐름과 의존성 방향을 뒤집는 데서 끝나지 않는다.
핵심은 의존하는 대상이 '구체'에서 '추상'으로 바뀌었다는 점이다. 즉, 방향을 바꾸는 것이 아니라 의존 대상을 바꾼 것이다.
구체적인 세부사항들은 뻣뻣하기 때문에 변경된다면 필연적으로 사용처에서도 영향을 받는다. 하지만 추상화된 인터페이스에 의존하면 내부 구현은 알 필요 없이 계약에만 의존할 수 있으므로 훨씬 유연하게 변화에 대응할 수 있다.
이는 소프트웨어가 본질적으로 ‘soft’해야 한다는 것, 변화에 쉽게 대응할 수 있어야 한다는 점을 설계 차원에서 보여준다.
OO 언어가 다형성을 안전하고 편리하게 제공한다는 사실은 소스 코드 의존성을 어디에서든 역전시킬 수 있다는 뜻이기도 하다. 고전적인 소프트웨어 아키텍처도 소스 코드 사이에 인터페이스를 추가함으로서 방향을 역전할 수 있다.
이러한 접근법을 통해 시스템의 소스 코드 의존성 전부에 대해서 방향을 결정할 수 있는 절대적인 권한이 생긴다. 즉 소스 코드 의존성이 제어흐름과 일치하도록 제한되지 않는다.
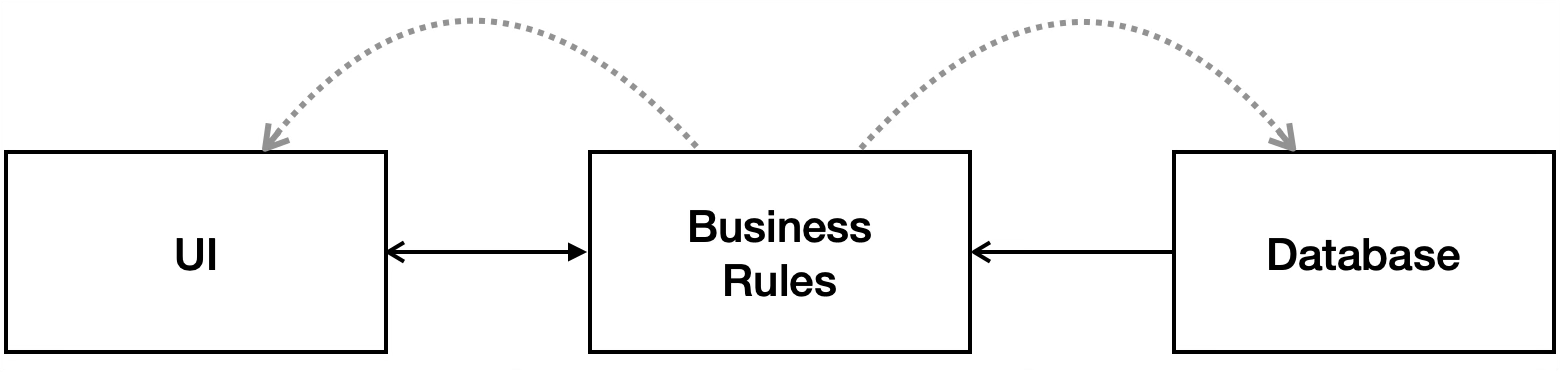
이렇게 함으로써 비즈니스 룰의 DB와 UI에 대한 의존성을 역전시켜서 DB와 UI가 비즈니스 룰에 의존하게 만들 수 있다. 비즈니스 룰을 소유한 코드 베이스에서 UI와 DB를 직접적으로 호출하지 않는다는 말이다. 이를 통해서 비즈니스 룰을 UI와 DB와는 독립적으로 배포할 수 있게된다. 배포 독립성을 가질 수 있는 배경이 되고 이것은 개발 독립성으로도 이어진다.
결론
OO란 다형성을 이용하여 전체 시스템의 모든 소스 코드 의존성에 대한 절대적인 제어 권한을 획득할 수 있는 능력이다.
OO를 사용하면 플러그인 아키텍처를 구성할 수 있고, 이를 통해 고수준의 정책을 포함하는 모듈은 저수준의 세부사항을 포함하는 모듈에 대해 독립성을 보장할 수 있다.